PostgreSQL High Availability on Kubernetes

In this post I will discuss why single-node PostgreSQL deployments are not a viable way to run PostgreSQL on Kubernetes in Production, as well as an overview of what needs to be done to protect yourself from data loss and downtime.
Why this post?
A few months ago I was in a call with a possible customer regarding their PostgreSQL workloads, support and requirements for High Availability (HA). The assigned seller and I tried to explain to a them what HA actually entailed. Their techie, on the call, insisted that they would deploy PostgreSQL to Kubernetes with PVC and by doing so would attain HA with no extra work, refusing to listen to why this was not enough.
As part of a Sales organisation I can easily pass this off as “just a lost sale”. Annoying, true. But no huge problem.
But the Techie in me can’t stop thinking about the consequence for the company. They think that they have a HA setup but they really don’t. My worry is that they will lose their data at some point.
It seems to me that the business side don’t realise how little the Kubernetes features actually help, when it comes to stateful deployments on Kubernetes. For true Production worthy deployments – you’ll need an operator to automate the deployment.
This post tries to explain why Kubernetes isn’t a Silver Bullet for highly available stateful workloads. We’ll use a PostgreSQL database as an example here. But I’m fairly sure the observations made here applies to other stateful deployments as well.
Stateless vs. Stateful deployments
Let first define Stateless vs. Stateful.
Stateless means that the calls coming in to an application doesn’t make change to the application – a call to a specific resource will always return the same result, regardless of what came before. Think of this as static HTML: no matter how often you load the homepage, it will never change.
Now lets expand this a bit. An application may have a stateful backend. For example a wiki uses some sort of backend to store the actual content of the pages. But, the wiki application itself doesn’t store anything. This means that you could kill the application, move it elsewhere (maybe a bigger server), hook it up to the backend storage .. and it would produce the same pages. Point being that the application itself (the wiki engine) can be replaced by a copy with no adverse effect. You could even run multiple wiki-engines connecting to the same backend storage. And they would all be identical.
Stateful, on the other hand, contains internal state. The storage backend for the wiki is a perfect example. Typically this is a database, like MySQL. If you were to update a row in the database, that would be a change in state. If you were to copy the database, you would now have two databases but since one is being used .. they will have different state after a while (since someone changed something on a page). If you used the copy of the original database instead – then all the changes made since the copy would be lost.
Kubernetes was originally built to manage stateless deployments. Stateful deployments have become possible relatively recently.
The single-node Kubernetes deployment
A typical single-node Kubernetes PostgreSQL deployment is just that: a single node (think: server) with a persistent volume (disk storage) attached.
If the PostgreSQL node fails, Kubernetes will create a new running node with the same Volume to the node.
This is the way Kubernetes self-heals: Failing nodes are replaced by new copies, identical to the originally deployed node.
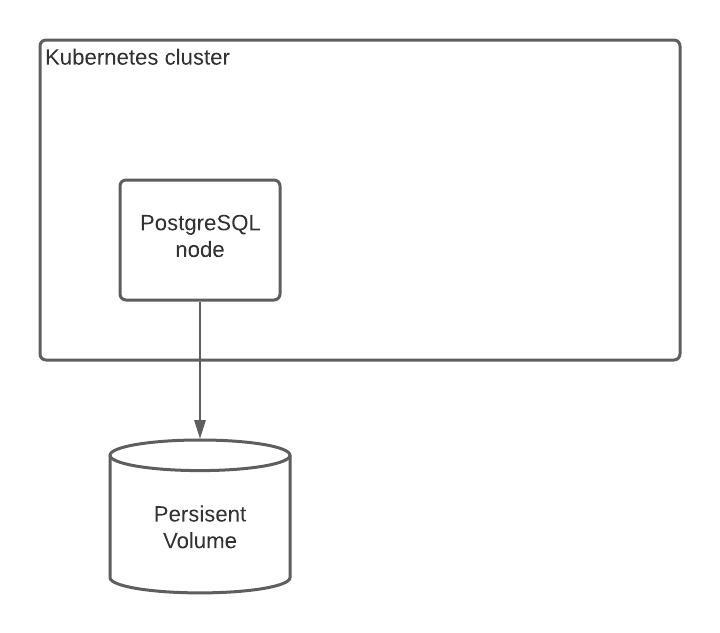
Why is this not High Availability?
This type of self-healing is fine for Stateless workloads. For Stateful workloads, such as a database, this is not enough. To understand why, we need to take a quick look into how databases are set up without Kubernetes, and why this is done.
Standard Database – High Availability Setups
When setting up a High Availability database we want to set up more than one database – at least two: a Primary database and a Standby database. In many cases more that two databases. Changes to data are replicated between the databases – logical or physical replication, or even a combination.
The Primary database is the one applications will use to update the state/contents of the database.
The standby database is there to take over, when the Primary fails. The is process is known as failover.
The “Replication and Failover Management” process is a simplified way of showing all the different processes monitoring the database and ensuring that failover is performed correctly.
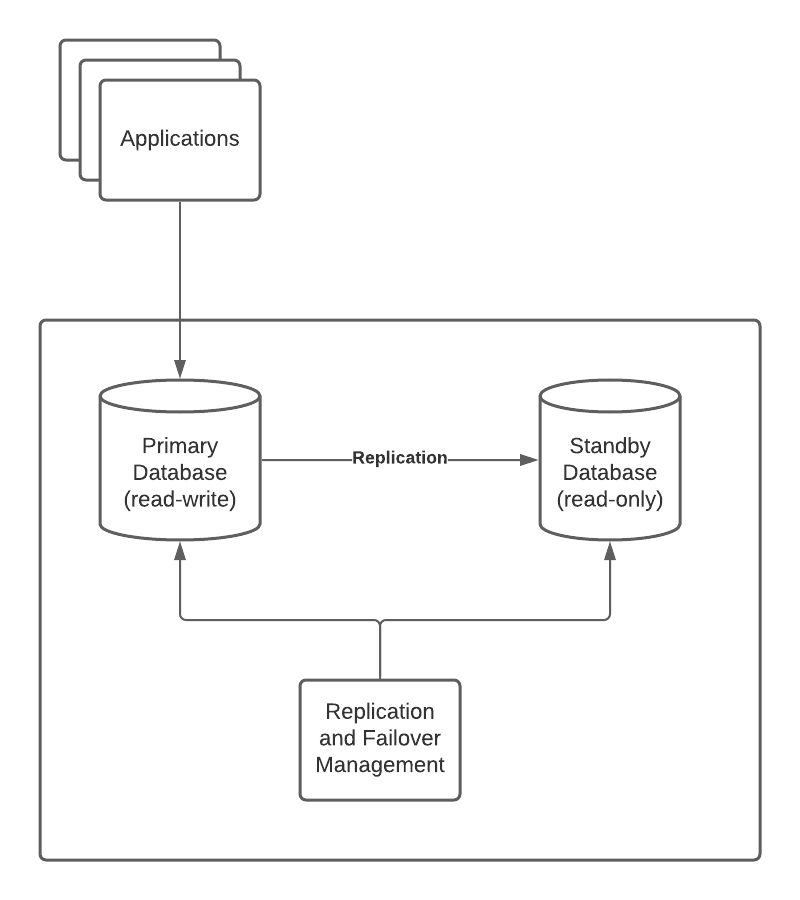
Failover happens can happen for a number of reasons. For example the server running the database can lose power, a disk can fail, .. any number of reason. In some cases restarting the database, with extra work needed is possible. In some case however that is not the case.
This type of setup is done for many reason:
- It allows failover, which will allow the applications to continue their work without too much interruption, should the active server fail.
- It safe-guards the data contained in the database. By replicating the data, that very act ensures that you have at least one clean copy of your data, should a hardware- or software-error result in file corruption.
Why you should avoid single-node database deployments?
Single-node database deployment (as the one illustrated above) are at risk of losing not only availability but also losing data.
One type of failure, where “restarting the database” with a new node deployed is not possible, is datafile corruption.
This type of failure is the result of a failed write to the one of the files used to maintain state in the database. In essence these files are the content of the tables and other objects in the database.
If such a datafile contains a faulty write – and this could be anything from a single wrong byte to several pages or blocks missing – the database will fail to read this area and generate an unrecoverable error.
No database can recover from this error automatically. This goes for databases running Kubernetes as well. No amount of self-healing in the cluster can resolve this – because the problem is not in the node running the database. It’s in the filesystem backing the database.
The only way to guard against this type of error, is by running a setup inside Kubernetes that looks like the ones run outside. In other words: Kubernetes is not a Silver Bullet when it comes to Stateful Deployments.
Where to find more information
There are several places on the web. For Kubernetes in general I would suggest http://kubernetes.io. For PostgreSQL http://postgresql.org and http://edbpostgres.com.
For information on different ways to deploy PostgreSQL, EDB maintains a list of Reference Architectures on GitHub.
For deploying PostgreSQL on Kubernetes (as it should be done) I would suggest Cloud Native Postgres from EDB
Kubernetes logo by kubernetes.ioPostgreSQL logo by PostgreSQL.org